Si no has estado viviendo en un templo budista tibetano durante los últimos años seguramente has tenido que implementar alguna vez una API REST que de servicio a una aplicación (web, móvil o lo que sea).
O por lo menos, una aproximación bastarda a lo que idealmente sería una API REST.
Con este artículo no quiero entrar en la definición de una “buena API REST”. Quizás en otro momento.
Pero sí quiero hacer hincapié en un aspecto importante y muchas veces ignorado,
bien sea para una API REST perfectamente diseñada o para la pequeña chapuza,
aborto, implementación rápida y flexible que has tenido que realizar en algún
momento: la autenticación de usuarios que acceden a la misma.
Aquí, como para muchas otras cosas, tenemos enfoques para todos los gustos y colores. Iremos estudiándolas una a una.
Pero la conclusión rápida que quiero que saquéis es que no es difícil hacer una API REST mínimamente rigurosa en lo que a autenticación se refiere. ¡Por lo que tenéis excusa para hacer las cosas bien!
Así que, ¡vamos a ello!
Principios básicos de autenticación
La autenticación intenta responder a la siguiente pregunta:
¿Puedo estar seguro de que la entidad que me habla es realmente quien dice ser?
Escena típica de película: el prota tiene que colarse en la guarida del malo. Para ello, llama a la puerta y debe responder correctamente a la pregunta secreta. Como es el prota, sabe la respuesta correcta, entra tranquilamente y desbarata los planes de su archienemigo. Si no fuese así, recibiría un tiro en la cara y la película habría finalizado.
Éste es el escenario más simple: ambos interlocutores conocen una contraseña compartida (la clave privada) que los autentifica mútuamente. La propiedad principal de dicha clave es también su mayor debilidad: debe ser secreta. Efectivamente, si alguna otra persona conoce la clave privada, no hay manera de diferenciarla de un interlocutor autenticado.
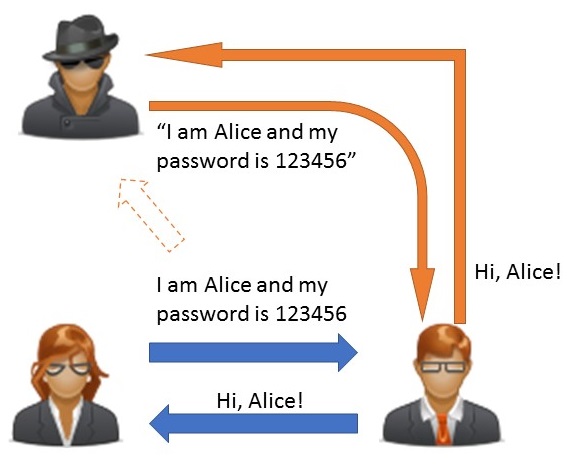
Autenticación con clave simétrica y posible robo de la misma
Por lo tanto, los grandes retos a los que se enfrentan los esquemas que optan por este enfoque son:
- ¿Cómo los interlocutores se ponen de acuerdo para establecer su clave privada?
- ¿Cómo se comunican la clave privada entre ellos en el proceso de autenticación?
Como respuesta a la primera pregunta, surgen algoritmos como el de Diffie-Hellman, que están fuera del alcance de este post.
Y como respuesta a la segunda pregunta, la regla de oro es sencilla: nunca digas la clave en alto. Traducido a lenguaje informático significa que nunca envíes tu clave en claro (es decir, sin encriptar). Y para ello, surgen muchos escenarios que veremos en la siguiente sección.
Otro enfoque es el de clave asimétrica. En este escenario, cada interlocutor posee un par de claves: una pública y otra privada.
La pública la conoce todo el mundo. La privada sólo la conoce él.
La clave pública y privada poseen estas dos propiedades:
- Un mensaje cifrado con la clave pública sólo podrá ser descifrado con la clave privada.
- Un mensaje cifrado con la clave privada sólo podrá ser descifrado con la clave pública.
La primera es la base de los sistemas de encriptación que utilizan este enfoque: si Alice le quiere enviar un mensaje a Bob y asegurarse de qué sólo Bob lo lea simplemente lo tiene que encriptar con la clave pública de Bob.
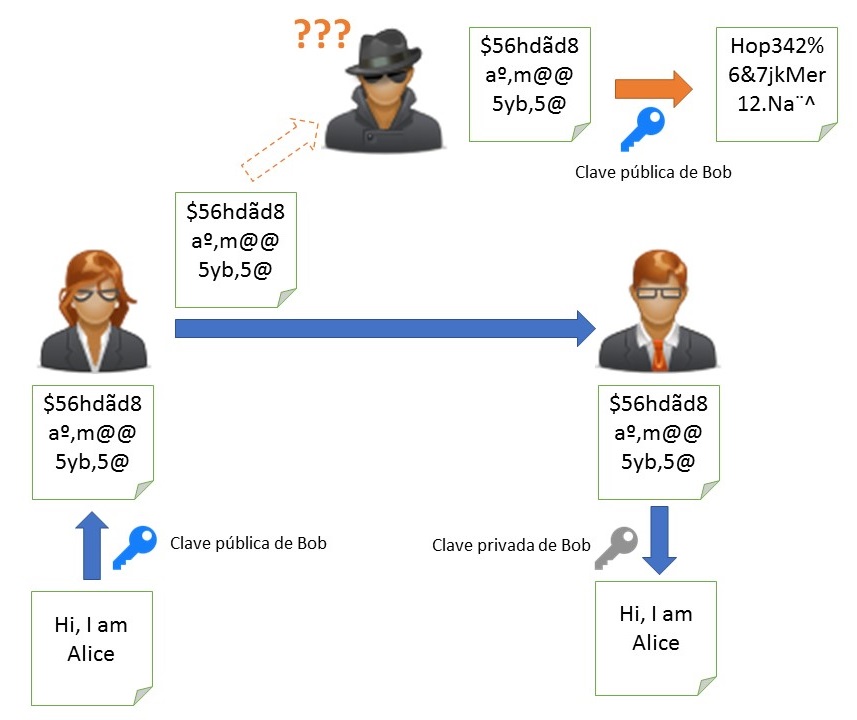
Encriptación con clave asimétrica e interceptación del mensaje cifrado
En cambio, la segunda es la base de los sistemas de autenticación que utilizan este enfoque. Alice envía un mensaje a Bob y lo firma, es decir, lo encripta empleando su clave privada. A continuación envía ambos a Bob, tanto el mensaje original como el mensaje encriptado (su firma). Para asegurarse de que ha sido Alice quién ha escrito el mensaje, lo único que tiene que hacer Bob es desencriptar la firma con la clave pública de Alice y compararlo con el mensaje original para comprobar que son exactamente iguales.
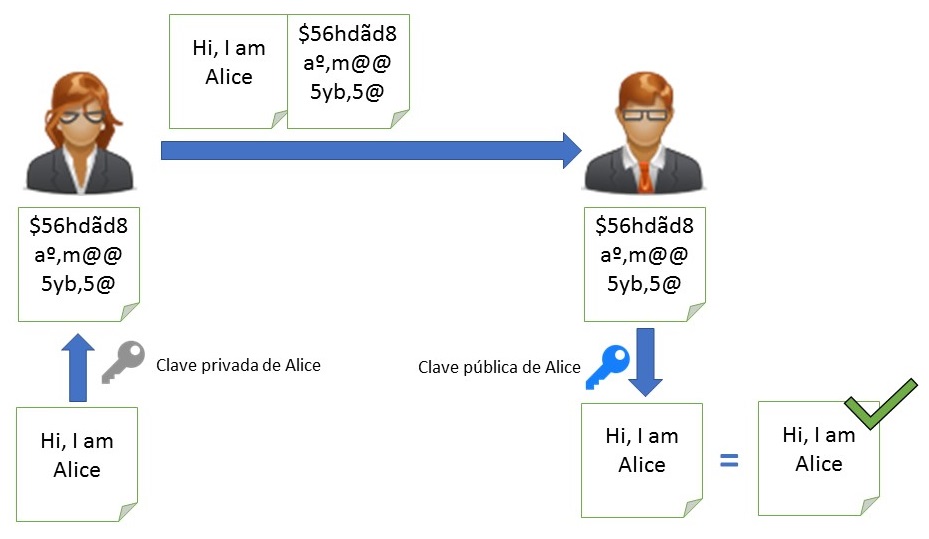
Autenticación con clave asimétrica y verificación
Si alguien intercepta el mensaje de Alice e intenta encriptarlo con la clave pública de Alice (la única disponible para todo el mundo), el resultado de la desencriptación (es decir, la firma) será diferente al mensaje original y Bob sabrá que no ha sido Alice quien lo ha enviado.
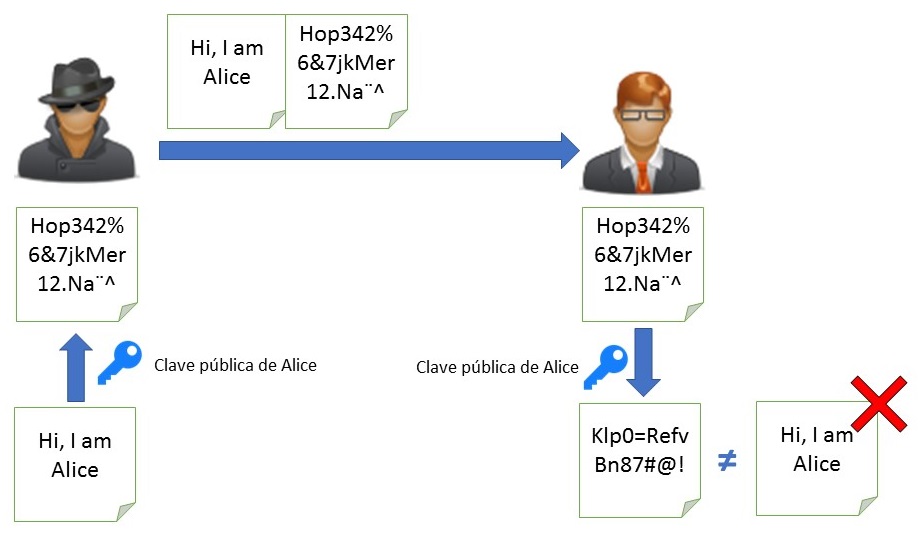
Interceptación de mensaje firmado con clave asimétrica y fallo en la verificación
Si os fijais, ya podéis ver un pequeño problema en este enfoque. Si el atacante consigue obtener ambos, tanto el mensaje original como su firma, y los envía tal cual a Bob, éste no podrá diferenciar si el mensaje lo ha escrito Alice o no. Para evitar esto, debemos añadir cierta aleatoriedad a la firma, como veremos más adelante.
Los retos de este enfoque se centran en cómo validar que la clave pública que tengo realmente es la de Alice y no la de cualquier otro. Aquí surgen cosas como PKG, los certificados digitales y toda una fauna y flora que seguramente más de una vez nos habrán dado algún dolor de muelas.
No nos meteremos en ese mundo. Como promete la descripción de este post, nosotros no vamos a complicarnos la vida para implementar seguridad en nuestra API.
Para mantenernos en la sencillez, supondremos que todos nuestros usuarios poseen una clave privada, una contraseña que sólo ellos conocen. A su vez, también poseen un nombre de usuario, o una API key que hará las veces de clave pública. ¡Ah! Y que utilicemos protocolos seguros para la comunicación extremo a extremo, como por ejemplo, HTTPS.
Partiendo de estos supuestos, veamos a continuación las diferentes leyes que debe cumplir nuestra API para cumplir con un mínimo de seguridad.
Primera ley: la clave privada sólo la conoce el usuario
Esta frase, que puede parecer simple de entender, a menudo es vapuleada a las primeras de cambio.
Nuestro sistema nunca, nunca, nunca debe conocer la contraseña del usuario.
Esto significa que nunca almacenaremos la contraseña en claro. Todas las fugas de contraseñas de sistemas aparentemente seguros han tenido éxito porque algún desaprensivo ha almacenado dichas contraseñas tal cual y se ha quedado tan ancho.
Para ello, se utilizan las archiconocidas funciones hash. Son funciones de encriptación que poseen dos propiedades interesantes:
- No es invertible. Es decir, no puedo recuperar el mensaje original a partir del mensaje cifrado.
- Es muy difícil que dos mensajes encriptados den el mismo resultado. Por lo que (casi) podemos asegurar que dos resultados de una función hash distintos pertenecen a mensajes originales distintos.
Por lo tanto, son funciones idóneas para nuestra casuística: no almacenemos la contraseña en claro, sino el resultado de aplicarle alguna función hash a la misma. De esta manera, nadie podría recuperar la contraseña original (porque no es una función invertible) y además dos hash distintos nos indican, casi con toda probabilidad, dos contraseñas distintas.
Por ejemplo, el resultado de aplicar la función hash SHA-256 a la contraseña MyAwesomeS3cReT es 2c3ce6087b5810f20c6aae1dc666c8a63557d33a7b38854779e8181f91a40239
En realidad, cuanto menor sea la probabilidad de que dos aplicaciones de una función hash den el mismo resultado, mayor será la resistencia a colisiones de dicha función hash.
Hay funciones hash que están “rotas”, es decir, se han descubierto algoritmos que permiten obtener el mensaje original en un número de pasos notablemente inferior a los necesarios si optásemos por la fuerza bruta.
Por supuesto, cuanto peor sea la calidad de la contraseña, más conocida será el resultado de cualquier función hash que utilicemos. Es más, para estas contraseñas simples una simple búsqueda en Google nos ofrecerá centenares de páginas web donde introduces el hash y te devuelve la contraseña original. Usan lo que se conoce como Rainbow Tables
Unificando todo:
- No almacenes tus contraseñas en claro, aplícales primero una funcion hash.
- No utilices funciones hash rotas como SHA-1 o MD5. Emplea SHA-256, que es el niño bonito de las funciones hash en la actualidad.
- En la medida de lo posible, intenta que las contraseñas sean fuertes. Si las especifica el usuario, oblígales que tengan una longitud mínima, o que usen mayúsculas, minísculas, números, caracteres especiales etc. En cambio, si las genera el sistema, es más fácil que éstas cumplan esas premisas, pero tampoco te pases, no vaya ser que ni siquiera tus usuarios las recuerden. Aquí tendrás que buscar una solución de compromiso: usabilidad frente a seguridad.
Y recuerda, aunque sea tu sistema el que genere las contraseñas de tus usuarios, aplícales una función hash antes de almacenarlas!!.
Segunda ley: ¡la clave privada sólo la conoce el usuario!
¡Sí, otra vez! No me he equivocado.
Y es que esta frase no sólo implica que no almacenemos la contraseña en claro.
Sino que tampoco nunca la transmitamos en claro.
Y ahora es cuando todos hemos tropezado en esta piedra: enviamos el hash de la contraseña y asunto arreglado… ¿verdad? ¡¿VERDAD?!.
Pues no.
Hacer esto, queridos niños, es a todos los efectos lo mismo que enviar la contraseña en claro.
Me explico.
Mi contraseña es MyAwesomeS3cReT, uso SHA-256 como función de hash y uso su resultado en las distintas peticiones para autenticar el usuario. Es decir, la API, al recibir una petición, recoge de ella el hash, la comprueba con el que está almacenado en la base de datos y, si son iguales, ¡eureka!, usuario autenticado.
¿Vemos el problema?
Cualquier persona que conozca el hash de nuestra contraseña podrá autenticarse sin problemas como nosotros antes la API.
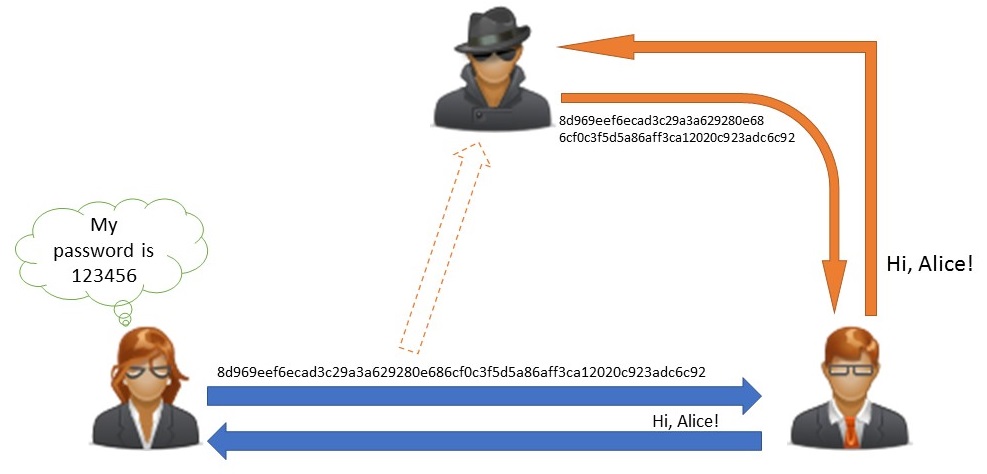
Envío simple de hash de contraseña e interceptación
El atacante no conoce nuestra contraseña original ¡y ni falta que le hace!.
Lo que tenemos que hacer es dotar de cierta aleatoriedad al componente que utilicemos para autentificar al usuario en cada una de las peticiones, con el objetivo de que, si un atacante obtiene dicho componente, no le valga para gran cosa.
Y es algo realmente sencillo, como veremos en la siguiente sección.
Un método sencillo para autenticar nuestras peticiones
Bauticemos las cosas. Ese componente que permite al usuario autenticarse frente a la API, esto es, decirle ¡soy yo y sólo yo! es lo que comunmente se conoce como token.
Hemos visto en la sección anterior que no podemos usar como token simplemente el hash de nuestra contraseña, porque sería muy sencillo que alguien se hiciese pasar por nosotros.
El objetivo es que, en cada petición, ese token sea distinto, de tal manera que si alguien lo obtiene, no pueda volver a utilizarlo. A esto se le llama otorgarle aleatoriedad al token.
Una manera sencilla de lograrlo es emplear la misma petición en la generación del token.
Cada petición siempre contendrá unos datos que parametrizan la acción que se va a realizar. Como mímino, la ruta del método de la API que queremos utilizar (/book por ejemplo, si esa es la ruta para obtener un listado de todos nuestros libros). Pero también puede contener parámetros en la query string (since=2017-04-27&until=2017-04-28 por ejemplo), el propio cuerpo del mensaje HTTP (el objeto JSON que contiene los datos, o en formato x-www-form-urlencoded o en multipart/formdata o en XML o en lo que sea) o incluso las propias cabeceras de la petición (donde especificamos el Content-Type, por ejemplo).
La idea es utilizar todos esos datos que hacen que dicha petición sea única para formar el token.
Es decir, el token sería el resultado de la función hash de la concatenación de los siguientes valores:
- La clave pública del usuario: su nombre de usuario, su API key, su identificador de usuario… Aquello que nos indique quién está realizando la petición.
- Todos los datos que hacen única la petición: su ruta (o path), su query string y sus parámetros (cuerpo y/o cabecera).
- El hash de la contraseña, la clave privada del usuario.
token = sha256(user_id + {path} + {query_string} + {parameters} + sha256(password))
Si ahora, un atacante obtiene dicho token, no podrá autenticarse como nosotros ante todo el sistema. Pero sí si repite exactamente la misma petición.
Es decir, si un atacante obtiene de alguna manera toda la petición, token incluído, de un recurso concreto (book, por ejemplo) de un usuario real y válido de nuestra API, al repetir él mismo dicha petición nuestro sistema no tendría manera de identificarlo como inválido y le daría acceso sin problema, eso sí, únicamente a ese recurso al que se refiere la petición.
Eso sí, si intenta utilizar el mismo token para un recurso diferente (author, por ejemplo), entonces nuestro sistema, al verificar el token, verá que no coincide y le denegará el acceso. Y esto se aplica también si varía la query string (realizar otro filtrado de los libros, por ejemplo), o si varía alguna de las cabeceras (si queremos obtener los datos por XML en vez de JSON, por ejemplo).
¡Hey! ¡Por lo menos hemos conseguido que el atacante no tenga acceso a toda la API simplemente obteniendo un token (como sí ocurre si el token es simplemente la contraseña “hasheada”).
Ahora bien, si queremos evitar este pequeño problema, la única manera es incluir en el token un componente temporal, un instante de expiración a partir del cual la petición no es válida.
Cabe decir que, para evitar complejidad computacional del lado del servidor, es aconsejable enviar dicho instante de expiración también en claro en nuestra petición.
De este modo, el token ahora se calcula aplicando la función hash a la concatenación de los siguientes elementos:
- La clave pública del usuario: nombre de usuario, API key, identificador de usuario…
- Todos los datos que hacen única la petición: su ruta (o path), su query string y sus parámetros.
- El instance de ejecución de la petición, o timestamp.
- El hash de la contraseña, la clave privada del usuario.
token = sha256(user_id + {path} + {query_string} + {parameters} + timestamp + sha256(password))
Una pequeña indicación con respecto al timestamp: utilizad siempre valores UTC. Nunca utilicéis sellos temporales en la zona horaria del usuario, u os volveréis locos para verificarlas en el servidor.
La siguiente figura resume todo el proceso.
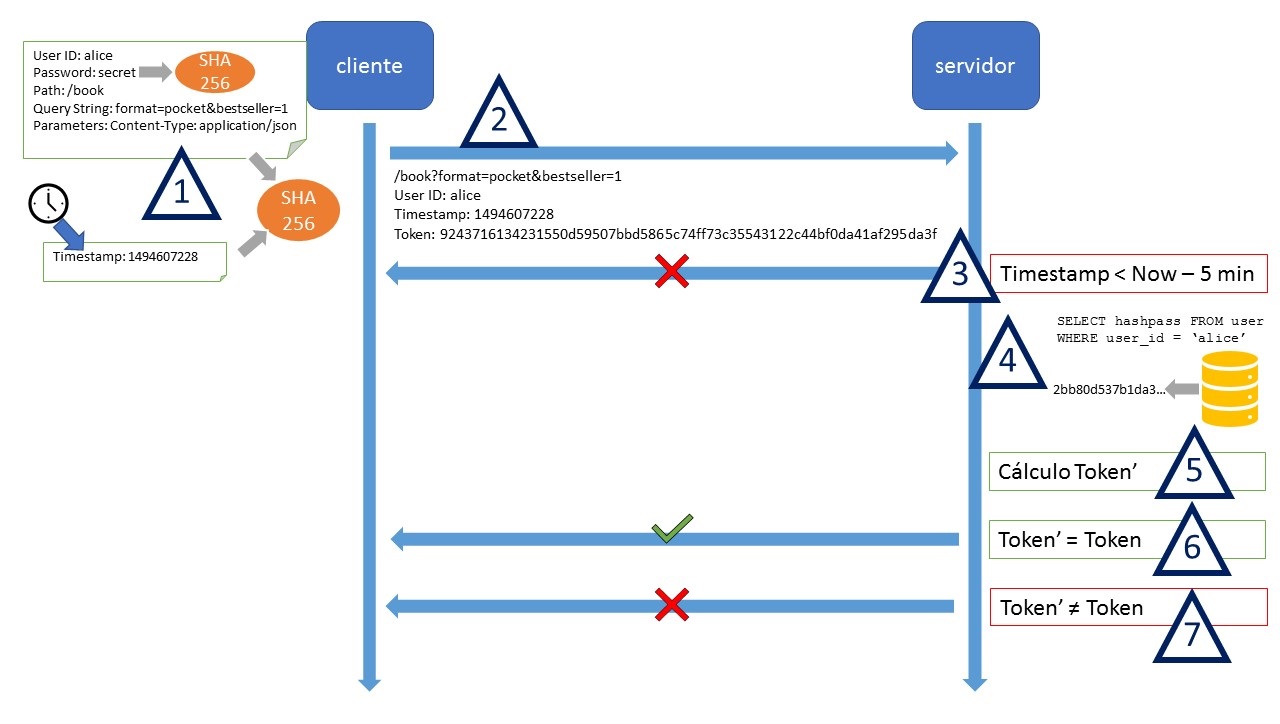
Método simple de autenticación segura
- La aplicación cliente compone el token tal y como hemos especificado arriba
- La aplicación cliente realiza la petición a la ruta especificada, con la query string y los parámetros necesarios, y a mayores también envía el identificador de usuario y el timestamp en claro.
- El servidor, antes de hacer nada, comprueba que el timestamp recibido se encuentra dentro de los parámetros aceptables. Por ejemplo, que no sea más antiguo que cinco minutos (es decir, las peticiones a la API tienen un periodo de validez de cinco minutos). Si la petición ha expirado, directamente la descartamos e informamos a la aplicación cliente.
- En caso contrario, el servidor utiliza el identificador de usuario para recuperar el hash de su clave privada (de una base de datos, por ejemplo).
- A continuación, recalcula el token. Fijaos que tiene todos los datos necesarios: el identificador del usuario, la ruta, la query string, los parámetros, el timestamp y el hash de la contraseña, que la acaba de recuperar en el paso anterior.
- Si el token recalculado es igual al token recibido, acepta la petición y ejecuta lo que tenga que ejecutar, devolviendo el resultado a la aplicación cliente.
- En caso contrario, rechaza la petición, notificando de ello a la aplicación cliente.
Conclusiones
Hemos hecho un pequeño y muy simplificado repaso de los aspectos básicos de autenticación y ciertas definiciones, siendo la más importante las funciones hash.
Finalmente, os he propuesto un método súper sencillo de aplicar para implementar autenticación segura en peticiones a una API.
Ahora bien, si queréis aplicar seguridad DE VERDAD (en negrita y mayúsculas) porque vuestra API así lo requiere (es un sistema crítico que tiene que cumplir ciertos requerimientos para que lo certifiquen, por ejemplo), entonces descartad esta aproximación.
Tened en cuenta que este método no evita problemas derivados a que el atacante tenga acceso al equipo del usuario. Por ejemplo, si la aplicación cliente es una aplicación web, nuestro hash de la contraseña podemos almacenarla en una cookie para no tener que pedirle la contraseña al usuario cada vez que realice una petición. Entonces, si dicho dispositivo tiene instalado un malware que consigue acceder a las cookies del navegador y las envía al servidor del atacante… we are screwed up. ¡Tiene todos los datos necesarios para suplantar la identidad de nuestro usuario cada vez que quiera!
No os confundais. Ahora el atacante ha obtenido el hash de la contraseña desde el mismo dispositivo del usuario no a través del propio canal de comunicación, que es lo que hemos evitado otorgando aletoriedad al token de autenticación.
En estos casos, entonces tenéis que optar por implementar estándares de seguridad. Concretamente, os recomiendo que echéis un vistazo a JSON Web Tokens (JWT) o si queremos ir más allá, implementar el estandar OAuth 2.0. Pero eso es carne para otro artículo.
Así a todo: pragmatismo. El método de este artículo es perfectamente válido para muchas APIs que podéis llegar a implementar y además (creo) es simple e intuitivo de entender. ¡Y no solo APIs! En general, para cualquier “artefacto” que requiera una autenticación de los usuarios.
En todo caso, ante cualquier duda, ya sabéis: ¡comentarios!.
¡Nos vemos en nada!