Como bien sabéis, si habéis estado atentos hasta ahora, Docker, para cada contenedor, crea una capa de lectura/escritura que es persistente mientras no destruyamos su contenedor.
En este artículo, mientras montábamos nuestro entorno de desarrollo, este problema lo solventamos creando un volumen de datos, pero un volumen muy particular, porque montamos un directorio de nuestro equipo local anfitrión en un directorio concreto dentro de nuestro contenedor. Esto nos permitía ir implementando nuestro código (con nuestras herramientas, preferidas, nuestro IDE, haciendo TDD si así lo quisiéramos…) en nuestro equipo local y dichas modificaciones quedaban reflejadas automáticamente en el contenedor.
Cuando quisimos pasar de esta fase de desarrollo a una publicación de nuestro proyecto
en una fase posterior (preproducción o producción), vimos que este mecanismo no era válido
y lo solventamos añadiendo directamente el código
de nuestro proyecto en el sistema de ficheros de la imagen (con el comando ADD de la especificación
Dockerfile).
Y esto realmente está muy bien, porque el código de nuestra aplicación no varía con el tiempo para una versión en concreta. Varía durante el desarrollo de una nueva versión. Una vez dicha versión esté implementada, creamos otra imagen añadiendo el nuevo código y lanzamos de nuevo el contenedor. Pan comido.
¿Pero qué ocurre con las bases de datos? Si tenemos un contenedor con un motor de base de datos ejecutándose (un MongoDB, un PostgreSQL, un MariaDB…), sí que es susceptible de variar con el tiempo. Es decir, si hacemos una inserción en la base de datos, el contenedor estará escribiendo en su capa de lectura/escritura. Y esto es extrapolable a otros sistemas de almacenamiento, por ejemplo, si queremos guardar las imágenes que suben los usuarios a nuestra flamante aplicación web.
Si por alguna razón el equipo anfitrión (nuestro servidor) se va al carajo… habremos perdido todos nuestros datos!!!
No tiene pinta de que éste sea un buen enfoque.
En este artículo vamos a ampliar el concepto de volúmenes de datos para nuestros contenedores, de tal manera que sean persistentes incluso aunque eliminemos nuestros contenedores y sobre los que podamos aplicar técnicas de backup & restore para que no nos pase como a los chicos de Gitlab

Un sysadmin de gitlab.com, hasta los ***** de todo (*)
(*)Gracias a Camilo por el GIF!!!
Ready, steady… Go!
Un volumen para una imagen de MariaDB
Los volúmenes son directorios que están alojados fuera del sistema de ficheros de nuestros contenedores, haciéndolos independientes del ciclo de vida de los mismos y permitiendo reutilizarlos aunque los contenedores vinculados desaparezcan.
Os dejo un enlace a la documentación oficial de Docker donde explican todo esto, para que le echéis un vistazo.
Allí, usan una imagen de PostgreSQL para sus ejemplos. Yo usaré una de MariaDB, por aquello de que veais otras opciones.
No me voy a complicar la vida montando un entorno desde cero, como hicimos en el caso de nuestro entorno Alpine + Apache + PHP, sino que utilizaré la imagen oficial de MariaDB.
Si os fijáis en su Dockerfile veréis que se basa en la imagen de Debian, y por ello pesa (comprimida) alrededor de 130MB, nada que ver con los irrisorios 2MB que pesaba nuestra imagen Alpine. Y no, por el momento no tenemos imagen oficial de MariaDB sobre Alpine. Son así de rancios.
Fijaos en la línea 99.
¿Veis ese comando VOLUME /var/lib/mysql?
Según la documentación, esta línea crea un punto de montaje en el
directorio /var/lib/mysql que es precisamente donde MariaDB va a almacenar los archivos de datos. A continuación, crea un
volumen de datos externo al UFS y lo vincula a dicho punto de montaje. El resultado:
todo lo que se intente escribir en dicho directorio no se hará en la capa de lectura/escritura manejada por el UFS, sino en el volumen asociado.
¿No me creéis? Personas de poca fe…
Abrid un terminal y picad:
docker volume ls
Este comando os listará todos los volúmenes creados en vuestro sistema. Inicialmente, debería de mostraros exactamente cero.
Ahora lanzamos un contenedor de nombre strawberry_daiquiri usando la imagen oficial de MariaDB:
docker run --name strawberry_daiquiri -e MYSQL_ROOT_PASSWORD=secret -d mariadb
El parámetro -e MYSQL_ROOT_PASSWORD=secret establece una variable de entorno en nuestro contenedor, de clave
MYSQL_ROOT_PASSWORD y de valor secret: el contenedor la usará inicialmente para establecer la contraseña
del usuario root de nuestra base de datos (esto viene explicado en la misma descripción de la imagen mariadb).
Tardará un poco en descargarse (132MB, ¿recordáis?) y veréis cómo inicia el proceso inicial de configuración de MariaDB. Tan pronto termine, volved a picar:
docker volume ls
¡Tendríais que tener un volumen creado!
Fijaos en el número enorme que aparece sobre VOLUME NAME: es el nombre de nuestro volumen. Lo usaremos dentro de nada.
Lo que vamos a hacer ahora es entrar en nuestro contenedor y modificar la base de datos:
> docker exec -ti strawberry_daiquiri /bin/sh
/ # mysql -u root -psecret
MariaDB [(none)] > CREATE DATABASE music;
MariaDB [(none)] > USE music;
MariaDB [(music)] > CREATE TABLE singers (id INT, name VARCHAR(64), PRIMARY KEY (id));
MariaDB [(music)] > INSERT INTO singers VALUES (1, 'Eddie Vedder');
MariaDB [(music)] > exit
/ # exit
Resumiendo: hemos creado una nueva base de datos con una nueva tabla y hemos insertado un nuevo registro en ella.
Ahora nos volvemos locos y nos cargamos el contenedor:
docker rm -f strawberry_daiquiri
Si volvemos a hacer un docker volume ls veremos que nuestro volumen sigue ahí.
Bien. Ahora lancemos un nuevo contenedor pero indicándole explícitamente qué volumen queremos que vincule al directorio /var/lib/mysql.
Por supuesto, el comando será el viejo y bueno docker run, pero usando el parámetro -v, cuya sintaxis es:
-v [NOMBRE DEL VOLUMEN]:[PATH AL DIRECTORIO DONDE QUEREMOS MONTAR EL VOLUMEN]
Lo que tenemos que ejecutar es:
docker run --name strawberry_daiquiri -e MYSQL_ROOT_PASSWORD=secret -v 2a3c4b0abdbfba66185ed6a7c2b37b565768e3166128f6010abb2ab144440c06:/var/lib/mysql -d mariadb
El uso de este parámetro -v en el comando docker run invalida el comando VOLUME del Dockerfile que vimos antes,
es decir, no crea un nuevo volumen de datos al iniciar el contenedor, sino que utiliza el que le hemos indicado.
Si volvemos entrar en nuestro contenedor para comprobar que todo sigue como lo habíamos dejado…
> docker exec -ti strawberry_daiquiri /bin/sh
/ # mysql -u root -psecret
MariaDB [(none)] > USE music;
MariaDB [(music)] > SELECT * FROM singers;
¡Hey! ¡Ahí tenemos a nuestro buen amigo Eddie Vedder!
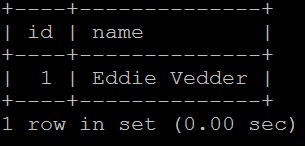
Nuestra fila insertada sigue ahí
¿Convencidos ahora? Nos hemos cargado nuestro contenedor pero nuestros datos siguen intactos. Es más, también hemos comprobado que los volúmenes son reutilizables entre distintos contenedores.
Esta sí es una aproximación interesante para contenedores de almacenamiento.
Los volúmenes, además de ser persistentes y reutilizables, también pueden ser compartidos por varios contenedores. En un principio iba a realizar una introducción a esto, pero lo descarté. Y la razón es que, por el momento, Docker no resuelve el acceso compartido a un volumen entre varios contenedores. Es decir, si nuestras aplicaciones no resuelven en código el problema de acceso compartido (usando cerrojos, semáforos, monitores o lo que más rabia os dé), es muy probable que al final tengamos un buen puñado de datos corruptos. Mi consejo: por el momento, no utilicéis esta posibilidad que ofrece Docker.
Bautizando volúmenes
Seguramente, ávidos lectores, os habréis dado cuenta que utilizar los nombres de volúmenes que nos genera Docker es de todo menos legible. Por ello es interesante bautizar a nuestros volúmenes.
Primero tenemos que crear un volumen con el siguiente comando:
docker volume create --name mariadb-data
Con ello, habremos creado un volumen con el nombre mariadb-data.
Para utilizarlo, se utiliza el comando docker run de nuevo con el parámetro -v:
docker run -d -p 3306:3306 -v mariadb-data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=secret mariadb
Con el anterior comando estamos lanzando un contenedor a partir de la imagen mariadb, en modo detached,
estamos publicando el puerto 3306 del contenedor en el puerto 3306 de nuestro host, establecemos la
variable de entorno MYSQL_ROOT_PASSWORD con la contraseña de root que queramos para nuestra base de datos,
y estamos montando el volumen mariadb-data en el directorio /var/lib/mysql.
A partir de aquí, todo funciona igual que en el caso anterior.
Un apunte: al montar el volumen en el directorio
/var/lib/mysql(tanto si optamos por Dockerfiles como si optamos por el comandodocker runcon el parámetro-v), si ya existen datos (ficheros, carpetas…) en dicho directorio, el montar el volumen encima no hace que desaparezcan sino que se trasladan al volumen. ¡No tengáis miedo a montar volúmenes, que no os cargaréis nada de vuestros contenedores!
Backup & Restore
Existe un parámetro
del comando docker run que nos permite montar los mismos volúmenes que está utilizando un contenedor en un contenedor nuevo.
Dicho comando es --volumes-from y su sintaxis es la siguiente:
--volumes-from [NOMBRE DEL CONTENEDOR]:[OPCIONES]
Las opciones son dos:
ro(read only) si queremos que el nuevo contenedor tenga acceso de sólo lectura a los volúmenes del otro contenedor.rw(read write) si queremos que el nuevo contenedor tenga acceso de lectura y escritura a los volúmenes del otro contenedor.
Si no especificamos nada, el nuevo contenedor heredará el tipo de acceso del otro contenedor. Y si tampoco hemos especificado nada
en el otro contenedor, entonces el modo por defecto siempre será rw.
Sabiendo esto, la estrategia que propone la gente de Docker para realizar copias de seguridad de nuestros volúmenes de datos es bastante artesanal, pero también sencilla de entender, implementar y automatizar. Se basa en los siguientes pasos:
- Partimos de un contenedor con volúmenes montados de los que queremos realizar una copia de seguridad. En aras de una mejor explicación, bauticemos las cosas: llamemos a este contenedor abraham_lincoln.
- Escogemos una imagen de un sistema operativo en el que venga incluída alguna herramienta de compresión. Por ejemplo, Ubuntu con la aplicación tar.
- Lanzamos un nuevo contenedor (que llamaremos benjamin_franklin) a partir de dicha imagen, con las siguientes restricciones:
- usará los mismos volúmenes que abraham_lincoln (esto lo especificaremos con el parámetro
--volumes-from). - montaremos un directorio de nuestra máquina anfitrión en un directorio específico del sistema de ficheros del contenedor, que llamaremos
directorio backup (esto lo haremos como ya sabemos, a través del parámetro
-v). - el comando que ejecutará benjamin_franklin al ser lanzado será, precisamente, uno que comprima los directorios sobre los que se han montado los volúmenes de abraham_lincoln y que el resultado lo almacene en el directorio backup.
- usará los mismos volúmenes que abraham_lincoln (esto lo especificaremos con el parámetro
Fijaos que:
- Al utilizar
--volumes-from, benjamin_franklin tendrá los mismos directorios que los vinculados a los volúmenes de abraham_lincoln exactamente con el mismo contenido. Por lo tanto, al comprimir el contenido de dichos directorios dentro de benjamin_franklin, estamos comprimiendo el mismo contenido que posee abraham_lincoln. - Al almacenar el resultado de la compresión en un directorio que está montado en la máquina anfitrión, tendremos dicho resultado ya disponible en la máquina anfitrión, por lo que el contenedor morirá pero nuestros archivos comprimidos estarán a salvo en nuestro equipo local.
Es decir, al final lo que tenemos es un procedimiento por el cual comprimimos los datos de los volúmenes de abraham_lincoln y los almacenamos en nuestro equipo anfitrión. A partir de aquí, podemos hacer lo que queramos con ellos: moverlos a un disco externo, subirlos a un sistema de almacenamiento de terceros como Amazon Glacier o jugarnos el pescuezo y dejarlos ahí mismo, en nuestro equipo anfitrión.
Venga, que lo estáis pidiendo a gritos. ¡Vamos a por un ejemplo!
Creamos el contenedor abraham_lincoln a partir de la imagen mariadb usando el volumen que habíamos llamado mariadb-data:
docker run -d --name abraham_lincoln -p 3306:3306 -v mariadb-data:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=secret mariadb
Venticuatro horas y miles de inserciones después, lanzamos a benjamin_franklin para que haga el trabajo sucio:
docker run --rm --name benjamin_franklin --volumes-from abraham_lincoln -v /c/Users/moises/backups:/backup ubuntu tar cvf /backup/backup.tar /var/lib/mysql
El comando
--rmfuerza la eliminación del contenedor una vez éste termina.
En el directorio local /c/Users/moises/backups tendremos el archivo backup.tar con nuestra copia de seguridad de todas las bases de datos.
Si ahora ocurre un desastre y tenemos que restaurar una copia de seguridad de nuestra base de datos, simplemente ejecutamos:
docker run --name bill_clinton --rm --volumes-from abraham_lincoln -v /c/Users/moises/backups:/backup ubuntu tar xvf /backup/backup.tar
Es decir, realizamos el proceso inverso: volvemos a lanzar un nuevo contenedor a partir de la imagen de ubuntu, que utilice los volúmenes de abraham_lincoln (para tener los directorios cuyo contenido queremos restaurar), que tenga montado en el directorio backup el directorio del equipo anfitrión donde tenemos la copia de seguridad, y que descomprima dicha copia de seguridad en los directorios de los volúmenes de abraham_lincoln.
Por supuesto, todo esto no lo haríamos a mano, sino que tendríamos scripts que ejecutasen el proceso de backups de forma periódica y tendríamos nuestro script de restauración para que podamos ejecutarlo rápida y directamente.
En mi (pequeña) experiencia con Docker, he visto que a veces va a ser necesario “reiniciar” el contenedor abraham_lincoln con
docker stopseguido de undocker startpara que el motor de base de datos vea los datos actualizados desde el volumen restaurado. Tenedlo en cuenta en vuestras pruebas.
Eliminando volúmenes
Si finalmente queremos eliminar de manera definitiva nuestro volumen, simplemente tendremos que ejecutar el siguiente comando:
docker volume rm mariadb-container
Conclusiones
Lo que hemos visto hoy:
- Cómo crear volúmenes de datos en nuestros Dockerfiles con la instrucción
VOLUME - Como listar los volúmenes creados con el comando
docker volume ls - Cómo crear volúmenes por línea de comandos con el comando
docker volume create - Cómo vincular volúmenes a nuesros contenedores con el parámetro
-vdel comandodocker run - Cómo establecer variables de entorno en nuestros contenedores con el parámetro
-edel comandodocker run - Cómo realizar un proceso de backup & restore de nuestros volúmenes.
- Cómo eliminar definitivamente un volumen.
Ahora es el momento de ponerse pragmáticos.
Si bien el uso de Docker para la parte estática de nuestros proyectos (el código) suponía un buen número de ventajas (nos permitía montar entornos idénticos en las distintas fases: desarrollo, testing, preproducción, producción), ¿el hecho de dockerizar bases de datos supone también una gran ventaja?
Pues la respuesta es que no tanto.
Al fin y al cabo, necesitamos un proceso de backup & restore que sigue siendo demasiado artesanal, cuando otras alternativas cloud como Cloud SQL de Google o RDS de Amazon nos ofrecen múltiples herramientas de Snapshot, copias de seguridad, restauración… muchísimo más potentes y sencillas de usar.
Mi consejo: dockerizad bases de datos en la fase de desarrollo. Es una manera sencilla de independizar las bases de datos entre distintos miembros del equipo (compartir una base de datos en desarrollo es una muy mala idea), sin necesidad de tener que instalar un motor de base de datos en cada equipo (con el consiguiente consumo de recursos) y ahorrándote los posibles problemas derivados de que haya distintas versiones de los mismos motores en distintos equipos de desarrollo.
Podéis dockerizar también las bases de datos de vuestros entornos de testing, sobre todo porque se adapta muy bien a la integración contínua. Tened un volumen creado ad hoc con vuestros datos de pruebas y cada vez que ejecutéis una batería de tests de integración realizad el siguiente proceso:
- Realizáis un backup del volumen.
- Lanzáis un contenedor de base de datos vinculado a dicho volumen.
- Ejecutáis el siguiente test.
- Restauráis el volumen con la backup del paso 1 para dejarlo en su estado inicial (porque cada test de integración debe ser idempotente, es decir, su estado no puede influir en el resultado de los posteriores test que ejecutéis)
- Volvéis a 3.
Y esto, por supuesto, hacedlo de manera automática. Es decir, los pasos 1, 2 y 4 escribidlos en un script que pueda llamarse desde vuestro entorno de integración contínua.
Ahora bien, en vuestros entornos de preproducción y producción, no hay ninguna ventaja aparente en usar Docker para las bases de datos. Usad un servicio cloud como los descritos antes. O vuestras propias máquinas si los requerimientos del proyecto así lo indican. Lo único en donde debéis tener cuidado es que las versiones de base de datos entre vuestros entornos dockerizados y los no dockerizados sean perfectamente compatibles entre sí, para evitar sorpresas de última hora.
¡Por hoy nada más! La semana que viene (o quizás la siguiente más, porque a lo mejor no me da tiempo a preparar el artículo en siete días), usaremos todo lo aprendido hasta ahora para ver cómo montar un entorno completo perfectamente real, en lo que será el último artículo de Docker por el momento en Write Some Code!.
¡Nos vemos en nada!