En el anterior post vimos que una de las herramientas heredadas de Unix que utilizaba Docker eran los chroot. Con ellos, podíamos establecer para un proceso en qué directorio comenzaba su sistema de ficheros, su carpeta raíz. También dijimos que, en la gestión de dicho sistema de ficheros, Docker era bastante eficiente.
En este post veremos en qué consiste esta eficiencia y cómo la consigue Docker.
Las capas
Imaginémonos que tenemos dos entornos de ejecución para dos aplicaciones. Ambos se ejecutan sobre el sistema operativo CentOS 7. Pero la primera, es una aplicación basada en la API 6 de Java. Porque somos tipos duros. Y la segunda es una aplicación NodeJS 6.9.
Vamos a hacer el ejercicio mental de montar sendos entornos de ejecución en dos máquinas virtuales.
Para la primera máquina virtual, la que reproduce el entorno de ejecución de la aplicación Java, tendremos que instalar:
- El sistema operativo CentOS 7.
- La máquina virtual de Java para la versión 6 de su API.
Para la segunda máquina virtual, la de la aplicación NodeJS:
- El sistema operativo CentOS 7 again.
- El servidor NodeJS en su versión 6.9.
Fijaos en el primer punto de ambas máquinas, el sistema operativo CentOS 7.
¿Todos los ficheros binarios que componen dicho sistema operativo están duplicados en ambas máquinas? Por supuesto que sí.
Tendríamos algo como esto:
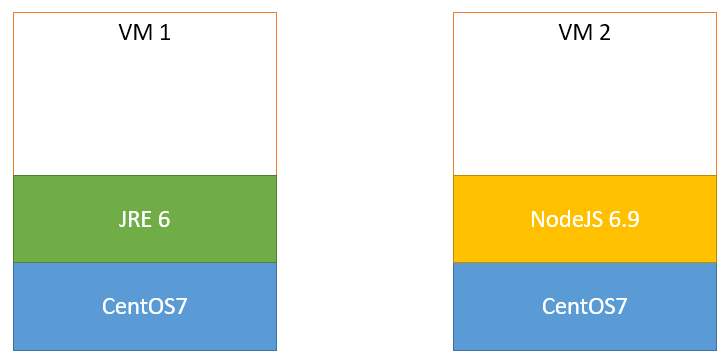
Entornos independientes (y duplicados) en dos máquinas virtuales
Esto no parece que sea muy eficiente. Es decir, ambas máquinas duplican exactamente los mismos binarios para el sistema operativo.
¿Qué pasaría si dichos binarios se pudiesen reutilizar entre ambas máquinas? En este escenario, ganaríamos eficiencia, ya que ambas máquinas compartirían los ficheros del sistema operativo (al fin y al cabo, es el mismo para ambos entornos). La única condición que necesitaríamos es que dichos binarios fueran de sólo lectura, para evitar que una escritura de la primera máquina cambiase el entorno de la segunda y ésta se fuese al garete.
En este segundo caso tendríamos:
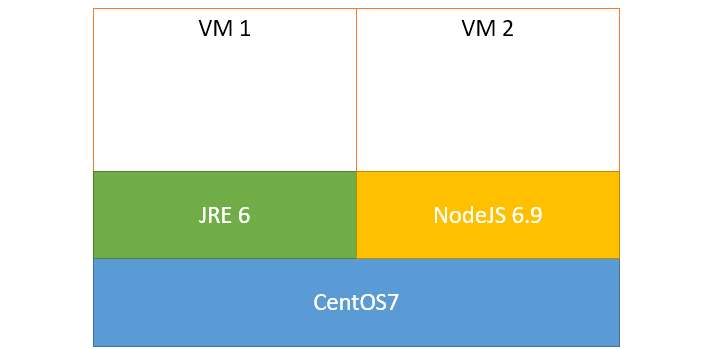
Entorno teórico de dos máquinas virtuales que comparten y reutilizan partes del mismo, en este caso, el sistema operativo
Bien, ahora bauticemos las cosas. Resulta que a un conjunto de binarios (por ejemplo, los que componen el sistema operativo CentOS 7) se le denomina una capa.
Este concepto de capas reutilizables es lo que emplea Docker para ganar eficiencia entre las “máquinas virtuales” (con todas las comillas que queráis) que gestiona. Es decir, la arquitectura de capas que emplearía Docker para modelizar los entornos del ejemplo sería la de la segunda figura, reutilizando la capa del sistema operativo. Y sí, sería de sólo lectura, y aunque parezca un impedimento grande, no lo es tanto, como veremos más adelante.
Si resulta que ahora necesitamos un tercer entorno, por ejemplo una aplicación web sobre CentOS 7 y NodeJS 6.9 pero empleando el framework Express 4, podríamos reutilizar las capas anteriores y nuestra nueva arquitectura quedaría de la siguiente forma:
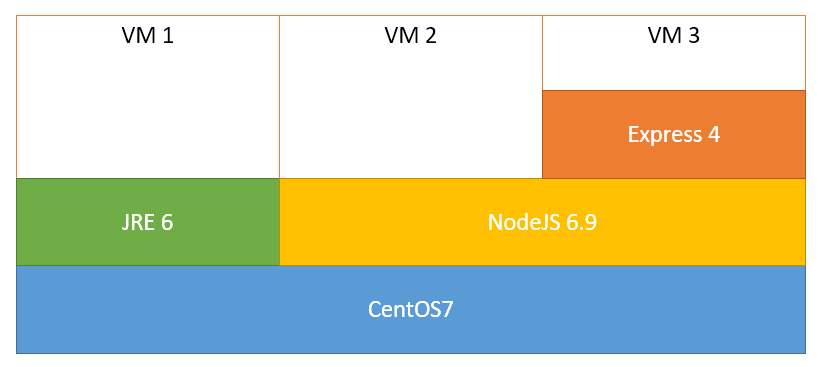
Entornos de tres máquinas virtuales que comparten y reutilizan partes: sistema operativo, servidor de aplicaciones etc.
¿Vemos la idea?
¿Y cómo se llama el chico que gestiona todo esto de reutilización de capas en Docker para que no se descontrole entre distintos entornos virtualizados? El Union File System (UFS). Y no me voy a meter a fondo con esto, más que nada, porque no lo controlo y no quiero meter la pata. Pero también porque, por el momento, no me ha hecho falta saber cómo funciona exactamente el UFS para entender Docker y poder trabajar con él.
Aunque, si estás leyendo esto y eres un experto en este tema, ¡no te cortes! Déjanos algo en los comentarios.
Por el momento continuamos con el siguiente concepto.
Las imágenes
Una imagen en Docker es cualquier conjunto vertical y adyacente de capas. Es decir, en la arquitectura de la figura anterior podríamos definir las siguientes imágenes:
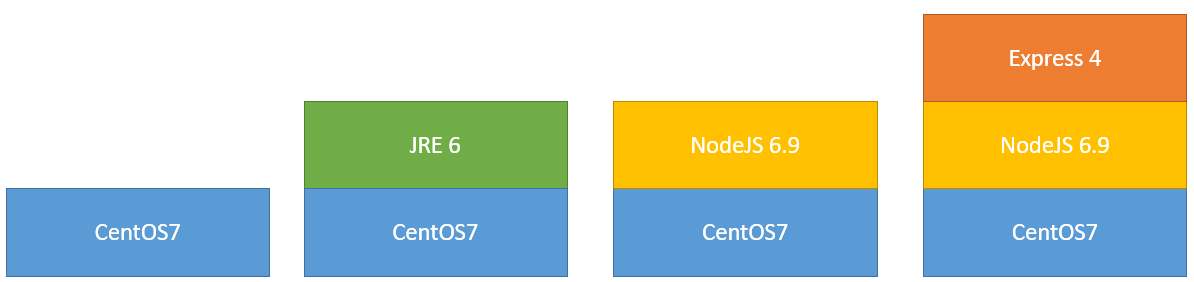
Imágenes posibles en una arquitectura de capas
- Una imagen con la capa de CentOS 7.
- Una imagen con la capa de JRE 6 sobre la de CentOS 7.
- Una imagen con la capa de NodeJS 6.9 sobre la de CentOS 7.
- Una imagen con la capa de Express 4, sobre la de NodeJS 6.9, ésta a su vez sobre la de CentOS 7.
Cada una de estas imágenes servirá como sistema de directorios de nuestras “máquinas virtuales”, teniendo en cuenta que:
- Las imágenes son de solo lectura.
- El UFS controla, para cada “máquina virtual”, si alguna de las capas de su imagen está siendo usada por otra “máquina virtual”, y si es el caso, la reutiliza.
¿Y si ahora queremos ejecutar una aplicación en alguno de nuestros entornos? Fácil: simplemente será una capa más a añadir encima de nuestra arquitectura. Es decir, los ficheros del aplicación componen una nueva capa que es gestionada por el UFS. Por ejemplo, para nuestra aplicación Express sobre NodeJS:

Imagen de una aplicación Express sobre NodeJS
Pero habíamos dicho que nuestras imágenes son de sólo lectura. Entonces, ¿qué pasa cuando nuestra aplicación realiza una escritura a disco (en un fichero, o en una base de datos)?
Para responder a esta pregunta hay que introducir el siguiente concepto (y último, por hoy).
Los contenedores
Os habréis dado cuenta del uso de las comillas cuando escribo “máquina virtual”. Además de porque ya sabemos que en Docker no existe este concepto exactamente, ya que se trata de una virtualización ligera, el otro motivo es que en Docker el término que se utiliza es el de contenedor.
Un contenedor es uno de esos procesos aislados y limitados en recursos de los que hablábamos en el anterior post y cuyo sistema de ficheros también le indicábamos. Como adelantamos arriba, el sistema de ficheros que va a utilizar ese proceso (o ya podemos llamarlo contenedor) será la imagen que le indiquemos: la de CentOS 7, la de CentOS 7 + Java etc.
Cuando lanzamos un contenedor en Docker, ademas de crear dicho proceso, le añade a su imagen una nueva capa de lectura/escritura que es donde realizará las modificaciones que se efectúen durante la ejecución del contenedor. Por último, también le asigna una interfaz de red virtual, para que el contenedor se pueda comunicar con el resto del mundo.
En esa capa de lectura/escritura es donde el proceso ve una versión concreta de los ficheros que son modificados. De esta manera, el estado de ejecución entre distintos contenedores que usen la misma imagen se mantiene independiente entre ambos, y esto permite al UFS poder reutilizar el resto de capas entre el resto de contenedores que las usen en sus imágenes.
¿Más o menos queda claro?
Un contenedor no es más que un proceso aislado y limitado en recursos que sólo ve como sistema de ficheros lo que la imagen le proporciona, más esa capa de lectura/escritura que guarda su estado actual.
Y fijaos: es un proceso. No es una máquina virtual. El lanzamiento de un contenedor es rapidísimo. Del orden de milisegundos. ¿Cuánto tiempo tardas en iniciar una máquina virtual con Virtualbox o VMWare? ¿Un par de minutos? ¿Unas cuantas decenas de segundos si tu máquina es potente? Pues eso.
Como todos los procesos, los contenedores se pueden pausar, se pueden reiniciar y se pueden matar definitivamente. Si los pausamos/reiniciamos, la capa de lectura/escritura permanece intacta entre ambos estados. Pero, si matamos un contenedor y volvemos a lanzar uno nuevo a partir de la misma imagen, la capa de lectura/escritura habrá desaparecido. ¡Claro, es un contenedor nuevo!
Así que ésta no es la manera adecuada de crear una capa de persistencia usando contenedores Docker. Pero esto lo veremos en posts futuros cuando presentemos el concepto de volúmenes.
Conclusiones
Bueno, la cosa ya se empieza a poner interesante. Hemos visto:
- Que Docker usa un sistema de capas, gobernado por el UFS, de tal manera que es capaz de reutilizarlas si varios contenedores hacen uso de las mismas.
- Que un conjunto de esas capas componen una imagen, que es lo que utilizará Docker para indicarle qué sistema de ficheros puede ver un determinado contenedor.
- Que los contenedores en Docker no son más que procesos aislados, limitados, con un sistema de ficheros basado en una imagen, con una capa extra de lectura/escritura que guarda su estado y con su propia interfaz de red para comunicarse con el resto del mundo.
Ya queda poco para que empecemos a picar comandos, que sé que lo estáis deseando: crearemos imágenes y lanzaremos contenedores. Pero antes vendrá otro post para definir unos cuantos conceptos sueltos que me han quedado en el tintero junto con un pequeño tutorial de cómo instalar Docker en máquinas sin soporte nativo para él.
¡Nos vemos dentro de nada!
P.S. Resulta que la imagen de cabecera de este post es el reflejo de un delito contra el patrimonio natural.