Hace un par de años, cuando trabajaba en el CITIUS, David Martínez nos impartió un pequeño seminario de una herramienta con la que había empezado a trastear hacía poco y lo tenía entusiasmado.
O bien porque no le presté mucha atención (lo siento, David, no eres tú, soy yo) o bien porque no supe entender su potencial en aquel momento, pero dejé aquello a un lado y me desentendí un poco de todo ese “nuevo” mundo.
Pero hace un año, más o menos, me llamó la atención el curso de Docker Essentials alojado en Capside Academy. Además, lo impartía el señor Javi Moreno, un verdadero crack con el que tuve el honor de dar mis primeros pasos en Javascript a partir de un curso que también impartió en el CNTG.
Si a Javi le apasionaba Docker, entonces la cosa tenía que ser interesante.
Así que desempolvé los apuntes que nos había facilitado David y cuando pude sacar algo de tiempo (en realidad, pasaron muchos meses desde que descubrí el curso), me lo devoré de cabo a rabo. Además, en paralelo, en el podcast de WeDevelopers emitieron un capítulo de, exacto… Javi Moreno hablando de Docker!. El universo me estaba enviando una señal, no cabía duda.
Puedo afirmar con una mano en el corazón que desde el primer momento en el que empecé a cacharrear con Docker ya tenía claro que lo iba a implantar en Tecalis. Ahora mismo lo estamos utilizando para nuestros entornos de desarrollo y ahora mismo estamos estudiando cómo prepararlo para nuestros entornos de preproducción.
Aunque mi experiencia con Docker no es exhaustiva, ni larga, creo que los conceptos básicos me han quedado bastante claros, así que voy a intentar plasmarlos aquí con el objetivo de ahorrarle un par de horas a cualquiera que quiera comenzar con ello.
Por otro lado, si eres un experto y ves que estoy metiendo la pata hasta el fondo… vapuléame en los comentarios! Sin piedad, en serio.
Empezamos!
¿Para qué se usa Docker?
En el 2010, la persona que había gestionado durante trece años el mantenimiento y evolución de
un importante sistema de información de la Xunta de Galicia decidió que era un buen momento
para cambiar de aires. Así que pidió la cuenta y se fué. Y como yo pasaba por allí, me cayó el marrón me ofrecieron esa responsabilidad.
Repito: un sistema desarrollado durante trece años. Cuando se picó su primera línea de código, no existía Google. Cuando yo lo cogí, el iPhone llevaba tres añitos entre nosotros. Os podéis hacer una idea.
El caso es que el entorno de desarrollo de dicho sistema era, cuanto menos… caótico. Mil dependencias en forma de librerías, algunas open source, otras código propietario, algunas obsoletas, otras directamente demasiado exóticas o desconocidas…
Ignorando temas de mantenibilidad, (que es decir mucho, ya lo sé, pero sólo tenía un añito de experiencia laboral!), el primer problema con el que me encontré es que dicho entorno de desarrollo estaba perfectamente instalado y configurado… en un único equipo. Como en los años 50, cuando queríamos/necesitábamos realizar una mejora, implementar un cambio, corregir un bug… un compañero se movía físicamente a dicho equipo durante los días que hiciese falta (es decir, dejaba su puesto de trabajo habitual durante días para irse a picar código a otro equipo que no era el suyo, a unas oficinas que no eran de su empresa y con unos compañeros que no eran los suyos) para implementar la nueva versión del sistema. Lo compilaba allí mismo, y enviaba los ejecutables por FTP al cabecilla de turno para que los desplegase.
Y procurábamos no pensar, por nuestra salud mental, qué pasaría si por alguna razón dicho equipo ardía o era zapateado escaleras abajo. Todavía se me ponen los pelos de punta.
Una locura.
Como comentaba, era un sistema bastante importante (aunque no lo parezca) así que las presiones por tener implementadas mejoras y correcciones eran prácticamente constantes todo el año. Estaba descartada la idea de hacer un trabajo “forense” e intentar replicar el estado de dicho equipo de desarrollo en otra máquina. Así que opté por utilizar una herramienta de VMWare (el vCenter Converter) que, básicamente, escaneaba un sistema de ficheros entero alojado en una máquina física y lo convertía en una máquina virtual. De esta manera, virtualicé (a cañonazos) el equipo de desarrollo, me lo metí en una memoria externa y, oye, por lo menos podíamos dormir tranquilos: ya teníamos una copia virtual del entorno de desarrollo, que podíamos ejecutar donde quisiéramos (siempre y cuando el equipo anfitrión fuera lo suficientemente potente) y los desarrolladores ya no tenían que estar trabajando entre dos sitios distintos. Quiero pensar que su calidad de vida incrementó enteros en aquel momento.
¿Por qué os cuento esta historia? Porque Docker te permite, entre otras cosas, replicar exactamente el entorno de ejecución de un proyecto, de una manera muchísimo más eficiente y rápida que la que buenamente implementé yo con el vCenter Converter. Eso sí, con matices que iremos viendo paulatinamente.
En realidad, si no empiezas tu proyecto usando Docker, puede ser bastante complicado replicar su entorno de ejecución a posteriori. Es más, en la historia que os cuento, sería como mínimo una tarea complicada y tediosa. Pero estas cosas las comentaremos más adelante en posts futuros.
Imaginad que puedo desplegar un entorno de ejecución de cualquier sistema/aplicación en un tiempo ridículo (del orden de milisegundos) y siendo lo más eficiente posible en el uso de recursos. Pues eso es Docker.
Partiendo de esto, podéis intuir que el paso de desarrollo a producción es indoloro (adiós a aquello de ¡en mi máquina funcionaba!). En todos los escenarios (desarrollo, testing, preproducción, producción…) tenemos exactamente el mismo entorno (el mismo sistema operativo, la misma base de datos, las mismas librerías… todo en las versiones exactas). El margen para los problemas se estrecha bastante.
Todo eso está muy bien, pero ¿cómo funciona?
En realidad, la tecnología que está en las tripas de Docker no es el último grito precisamente. Emplea herramientas que llevan con nosotros muchos, muchos años. Si eres un experto en entornos Unix, seguramente te suenen. Yo no lo soy, así que me sonaban vagamente cuando empecé con Docker.
En Unix tenemos desde hace muchos años las siguientes funcionalidades:
- chroot: básicamente le indica a un proceso que su sistema de ficheros empieza donde tú le digas. Es decir, cambias la raíz del sistema de ficheros del proceso (de ahí su nombre, change root).
- cgroups: se utiliza para limitar en recursos la ejecución de un proceso: memoria, ancho de banda, núcleos etc. categorizando los procesos en diferentes control groups.
- namespaces: útiles para aislar un proceso del resto de procesos. Es decir, poder hacerle creer a un proceso que es el único que se está ejecutando en toda la máquina.
Pues perfecto, si ejecutamos un proceso aislado, limitado en recursos y le decimos que la raíz de su sistema de ficheros está en un directorio donde tenemos almacenados casualmente los binarios de nuestro entorno de ejecución (sistema operativo, base de datos, servidor de aplicaciones etc), alehop!, acabamos de virtualizar dicho entorno a nivel de sistema operativo.
Y esto es la idea principal de Docker: virtualización ligera a nivel de sistema operativo. Usando procesos pequeños y rápidos en vez de pesadas máquinas virtuales. Y siendo muy eficientes en los binarios que componen nuestro entorno de ejecución, como veremos en futuros posts.
Estas son las tripas de Docker. La verdad detrás del truco, que necesitamos saber para no caer en lo que comentaba el bueno de Arthur C. Clarke: cualquier tecnología lo suficientemente avanzada es indistinguible de la magia.
Pero para nuestro día a día, lo único que tenemos que tener claro es que Docker maneja la siguiente arquitectura:
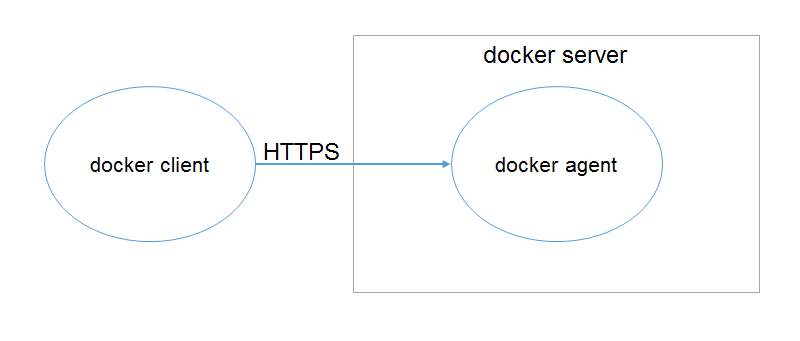
Modelo de componentes (muy simplificado) de Docker
Es decir, tenemos un intérprete de Docker, el docker client, que se comunica con el sistema Docker (el docker server) a través de una API REST bajo HTTPS cuyo punto de acceso está implementado en el proceso docker agent que se ejecuta en background.
Con cada comando que ejecutamos en Docker, por ejemplo:
docker run -ti alpine /bin/sh
en realidad estamos invocando una o varias peticiones HTTPS a dicha API REST. ¡Incluso podríamos comunicarnos con ella directamente empleando cURL por ejemplo!
Es el docker agent el encargado de procesar dicha llamada y comunicarse con el núcleo de Docker para que gestione la virtualización de nuestros entornos utilizando las tres herramientas Unix que veíamos más arriba.
Por último, decir que la máquina anfitrión, desde el punto de vista de Docker, es aquella que ejecuta directamente el docker server. Y para ello, el sistema operativo anfitrión debe soportar Docker de forma nativa. ¿Esto qué significa? Pues sencillamente, que tiene que implementar algo parecido a los chroots, cgroups y namespaces que veíamos más arriba. Es decir, tiene que darle las herramientas necesarias a Docker para que éste haga su magia.
Por el momento, basta con decir que cualquier sistema basado en Unix (Linux, MacOS) tiene soporte nativo de Docker. Y Windows 10 lo tiene en su versión Professional, aunque he de decir que mi experiencia por el momento me dice que está bastante verde. Para el resto de sistemas operativos (Windows 10 Home, Windows 8.1, Windows 7…) habrá que utilizar un pequeño atajo para poder trabajar con Docker. ¡Pero no adelantemos acontecimientos! Simplemente sabed que se puede.
Conclusiones
Lo sé. No ha sido un post muy exhaustivo, no tenemos código, ni comandos, ni sabemos cómo trabajar con Docker. Pero me parece interesante asentar bien los conceptos básicos para lo que viene después. Lo que hemos visto aquí:
- Docker te permite replicar entornos de ejecución en base a virtualización ligera a nivel de sistema operativo. Eso nos permite terminar de raíz con el problema de ¡en mi máquina funciona!
- Para realizar esa virtualización ligera, se apoya en tres herramientas que tenemos en Unix desde casi siempre: chroot, cgroups y namespaces, creando procesos aislados, limitados en recursos y que manejan un sistema de archivos que nosotros les decimos.
- Docker está implementado como una API REST sobre HTTPS. Cuando ejecutamos un comando, lo que realmente hacemos es invocar un método de esa API REST y Docker, tras el telón, hace su magia.
Por último, os invito de nuevo a escuchar el podcast de Javi Moreno hablando de Docker! en WeDevelopers. Y a realizar su curso de Docker Essentials en Capside-Academy. Son sólo 20€ y os aseguro que estarán bien invertidos. Así a todo, de vez en cuando publican algún código promocional a través de su cuenta de Twitter. También es altamente recomendable seguir a Javi en Twitter o poner su blog Programar en Cloud en tu lector de RSS favorito (y de paso, el mío también!). Habla de Docker, microservicios, testing… y un montón de cosas interesantes.
¡Nos vemos en el siguiente post!